Abstract
Large Language Models (LLMs) are indispensable in today's applications, but their inference procedure -- generating responses by processing text in segments and using a memory-heavy Key-Value (KV) cache -- demands significant computational resources, particularly under memory constraints. This paper formulates LLM inference optimization as a multi-stage online scheduling problem where sequential prompt arrivals and KV cache growth render conventional scheduling ineffective. We develop a fluid dynamics approximation to provide a tractable benchmark that guides algorithm design. Building on this, we propose the Waiting for Accumulated Inference Threshold (WAIT) algorithm, which uses multiple thresholds to schedule incoming prompts optimally when output lengths are known, and extend it to Nested WAIT for cases with unknown output lengths. Theoretical analysis shows that both algorithms achieve near-optimal performance against the fluid benchmark in heavy traffic conditions, balancing throughput, latency, and Time to First Token (TTFT). Experiments with the Llama-7B model on an A100 GPU using both synthetic and real-world datasets demonstrate improved throughput and reduced latency relative to established baselines like vLLM and Sarathi. This work bridges operations research and machine learning, offering a rigorous framework for the efficient deployment of LLMs under memory constraints.
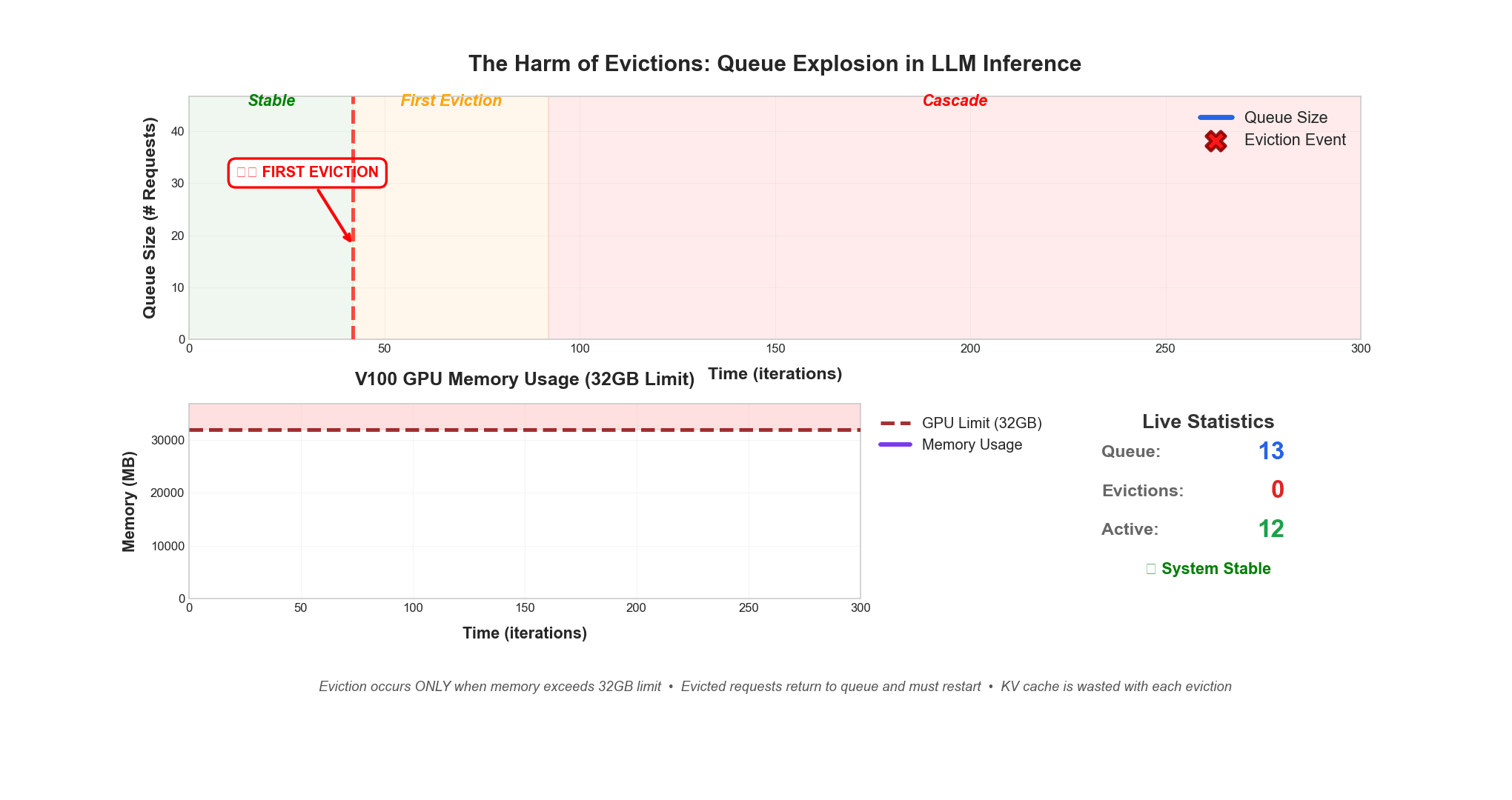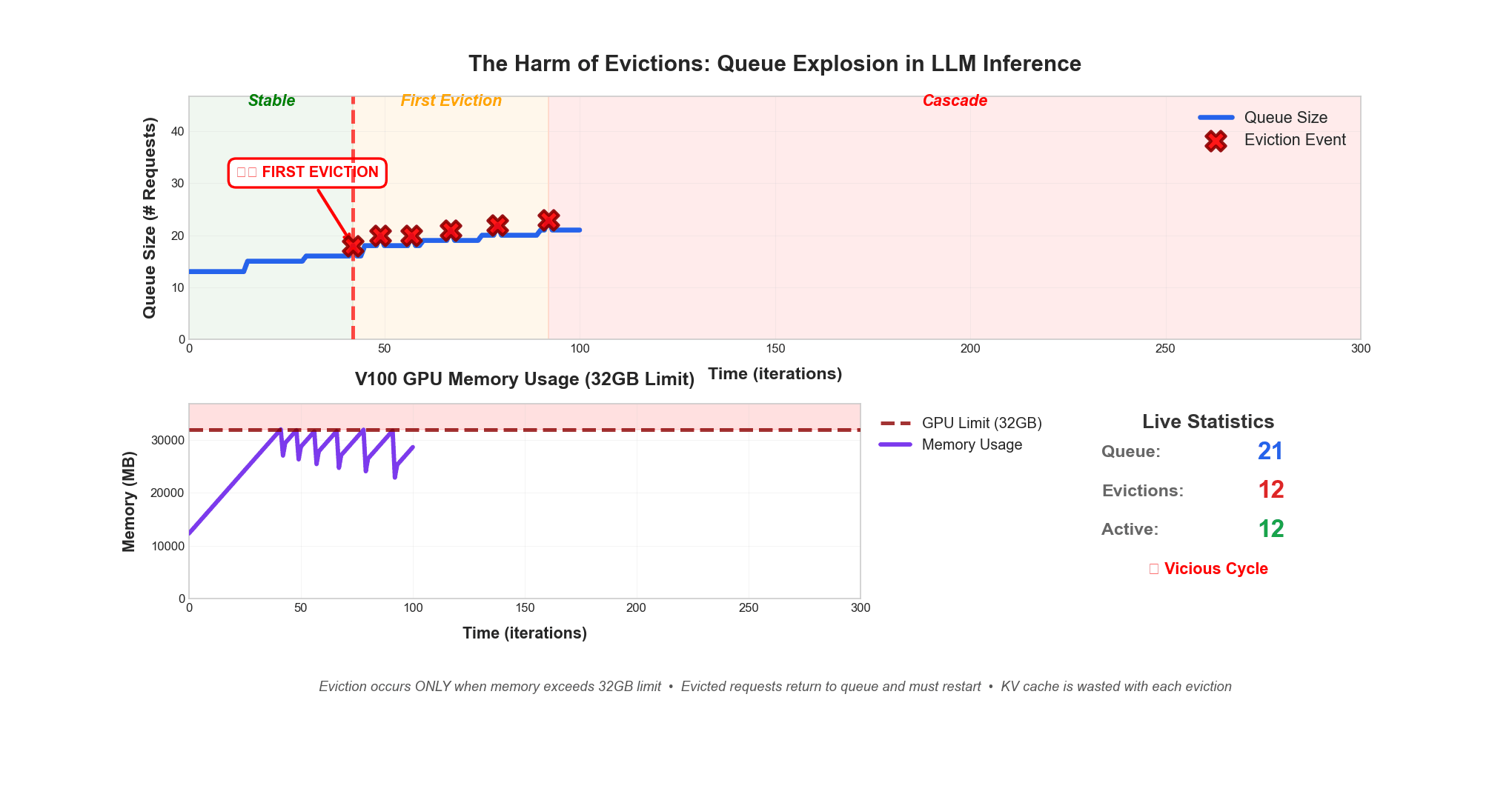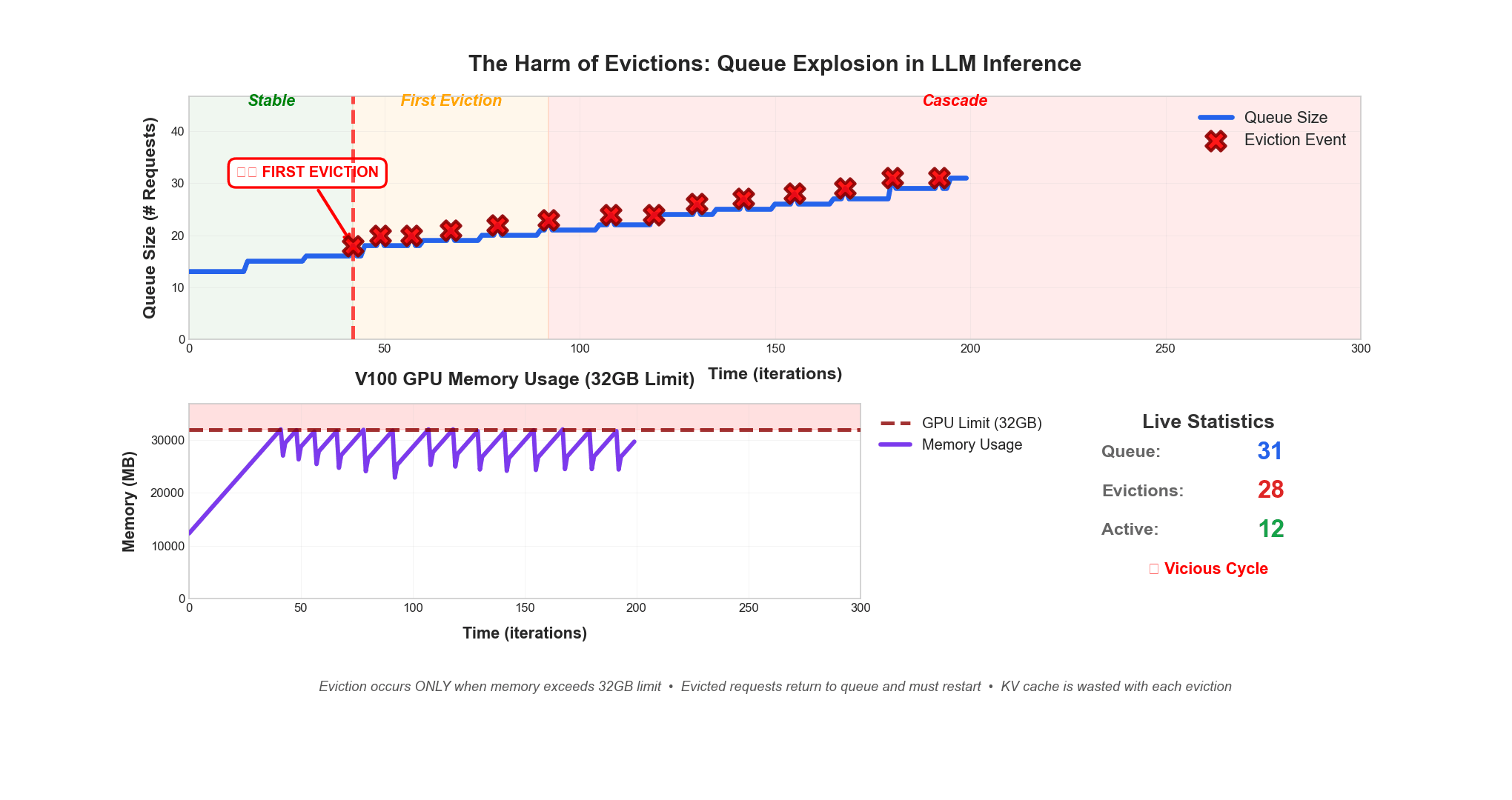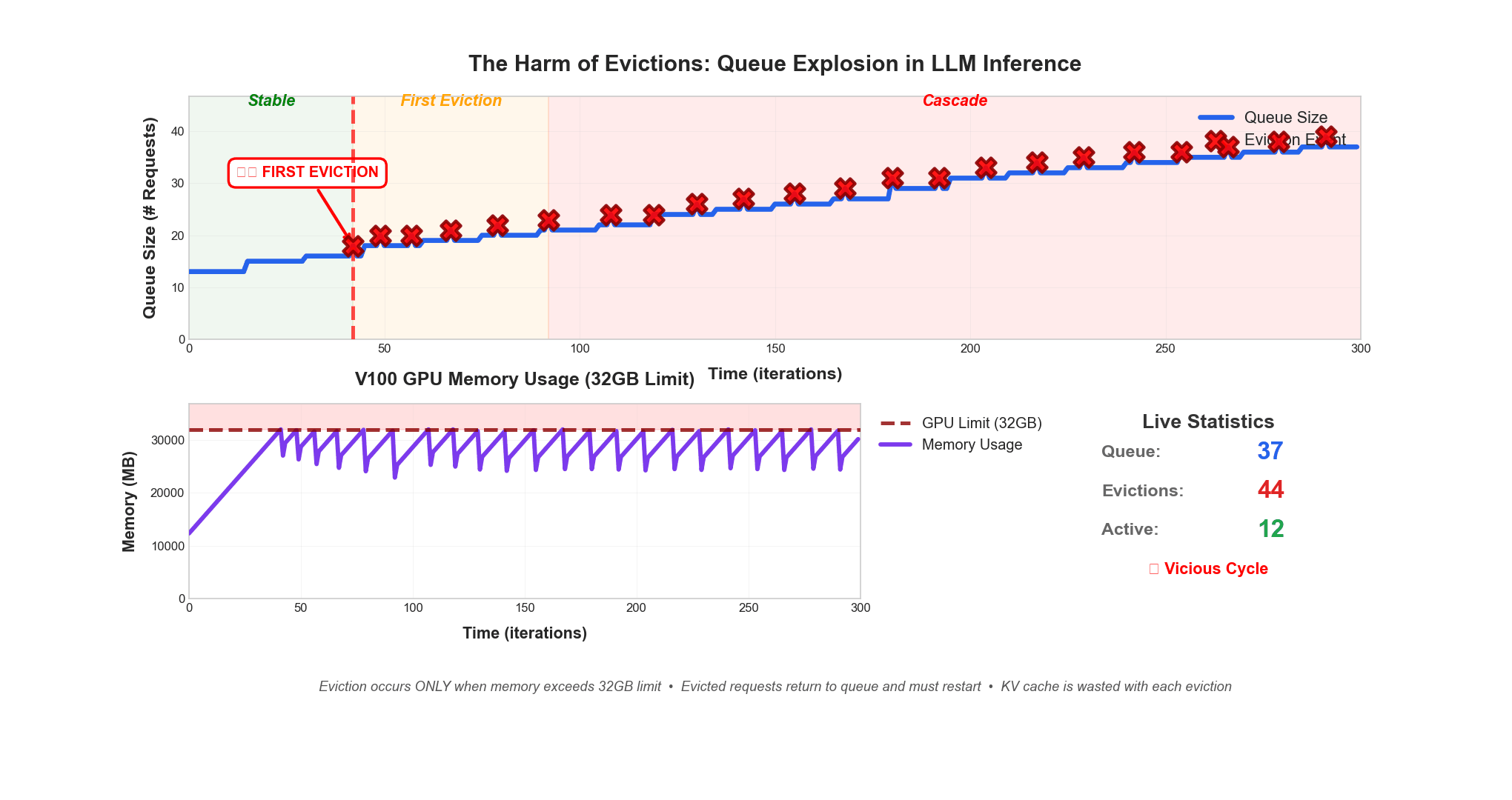
Eviction occurs only when memory exceeds 32GB limit. Evicted requests return to queue and must restart. KV cache is wasted with each eviction.

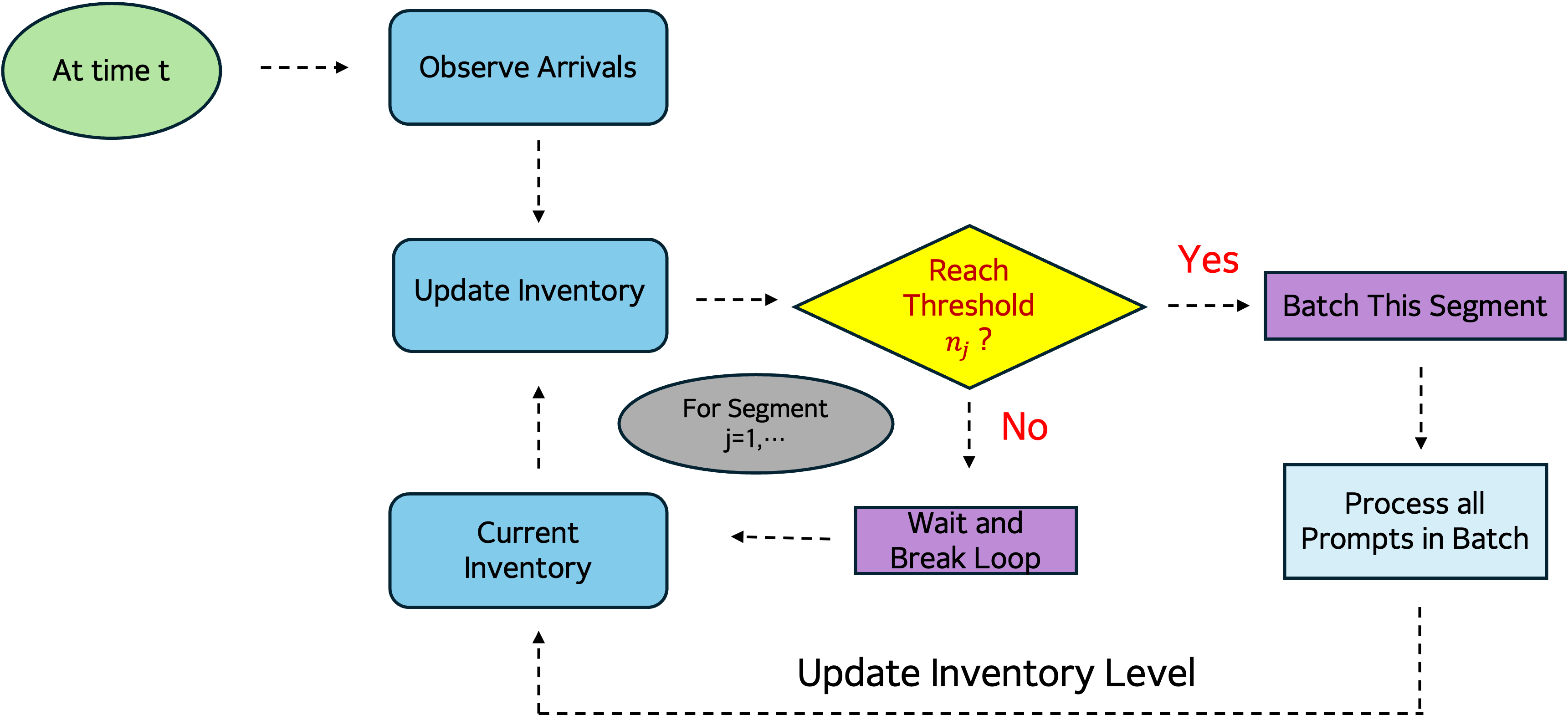
WAIT Algorithm: threshold based control
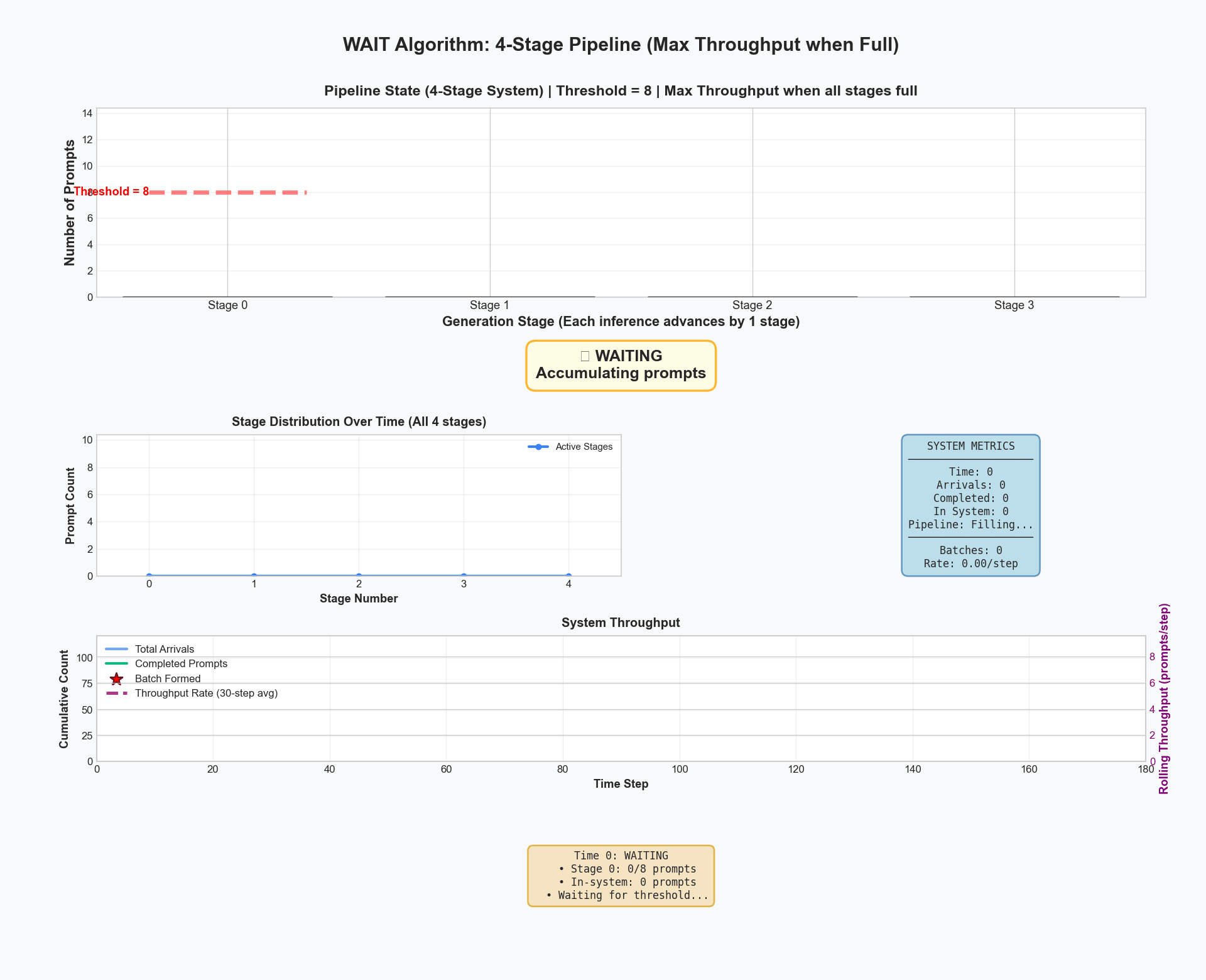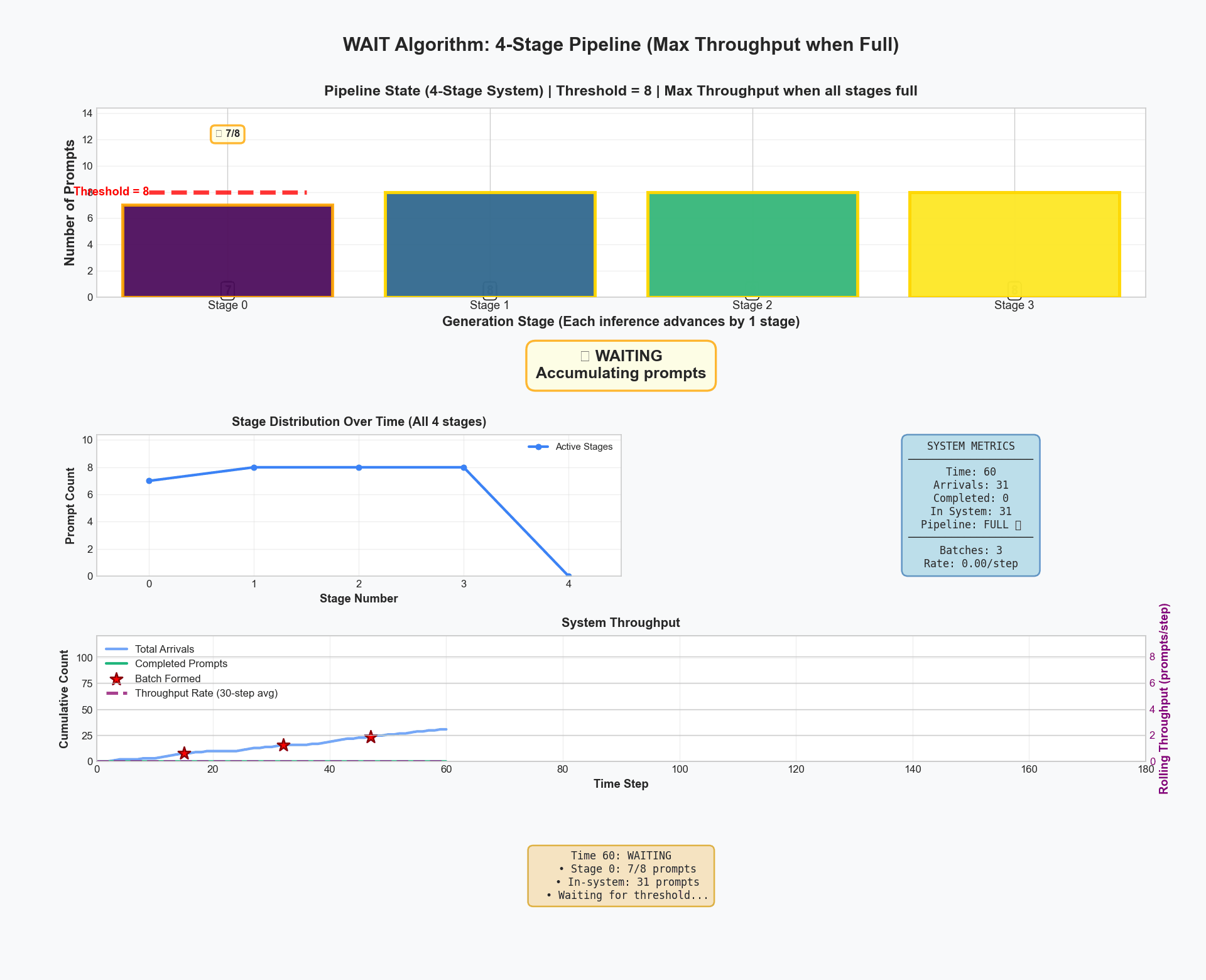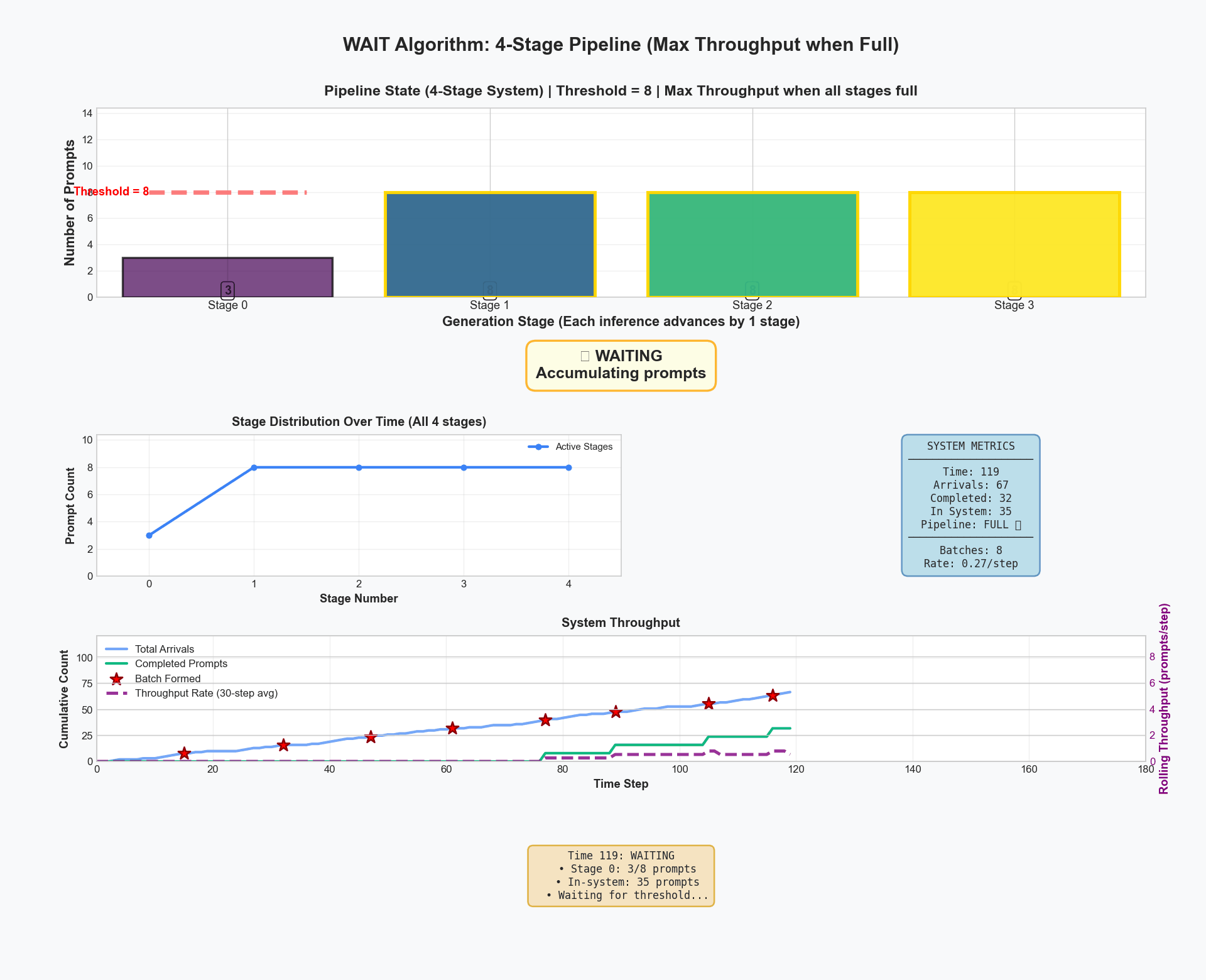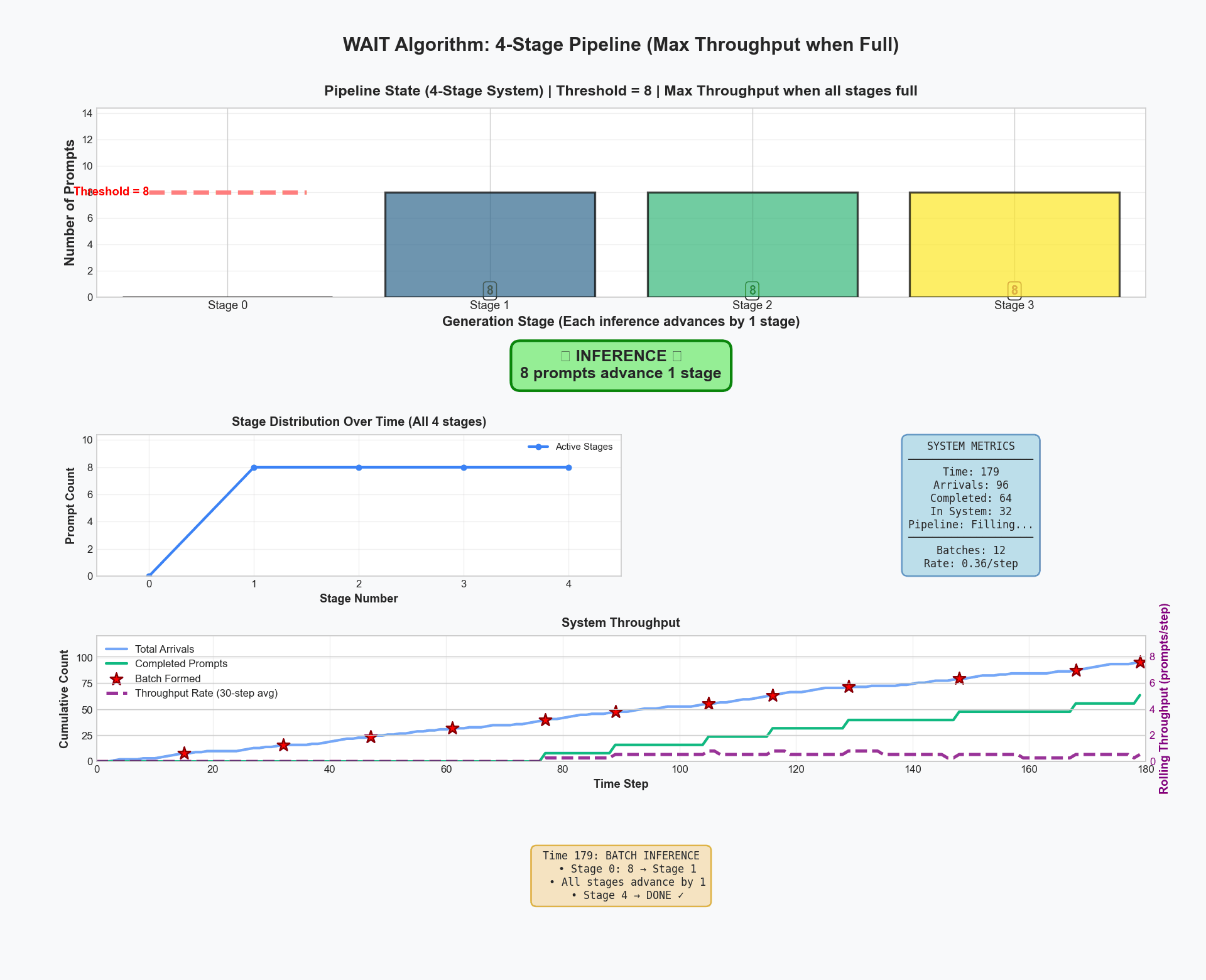
Here's WAIT running on a 4-stage pipeline. Initially, we accumulate requests. At time 20, we hit our threshold of 8 requests. From then on, the system maintains exactly 8 requests per stage in steady state. Notice the perfect synchronization - no memory spikes, no evictions, just smooth, efficient processing.
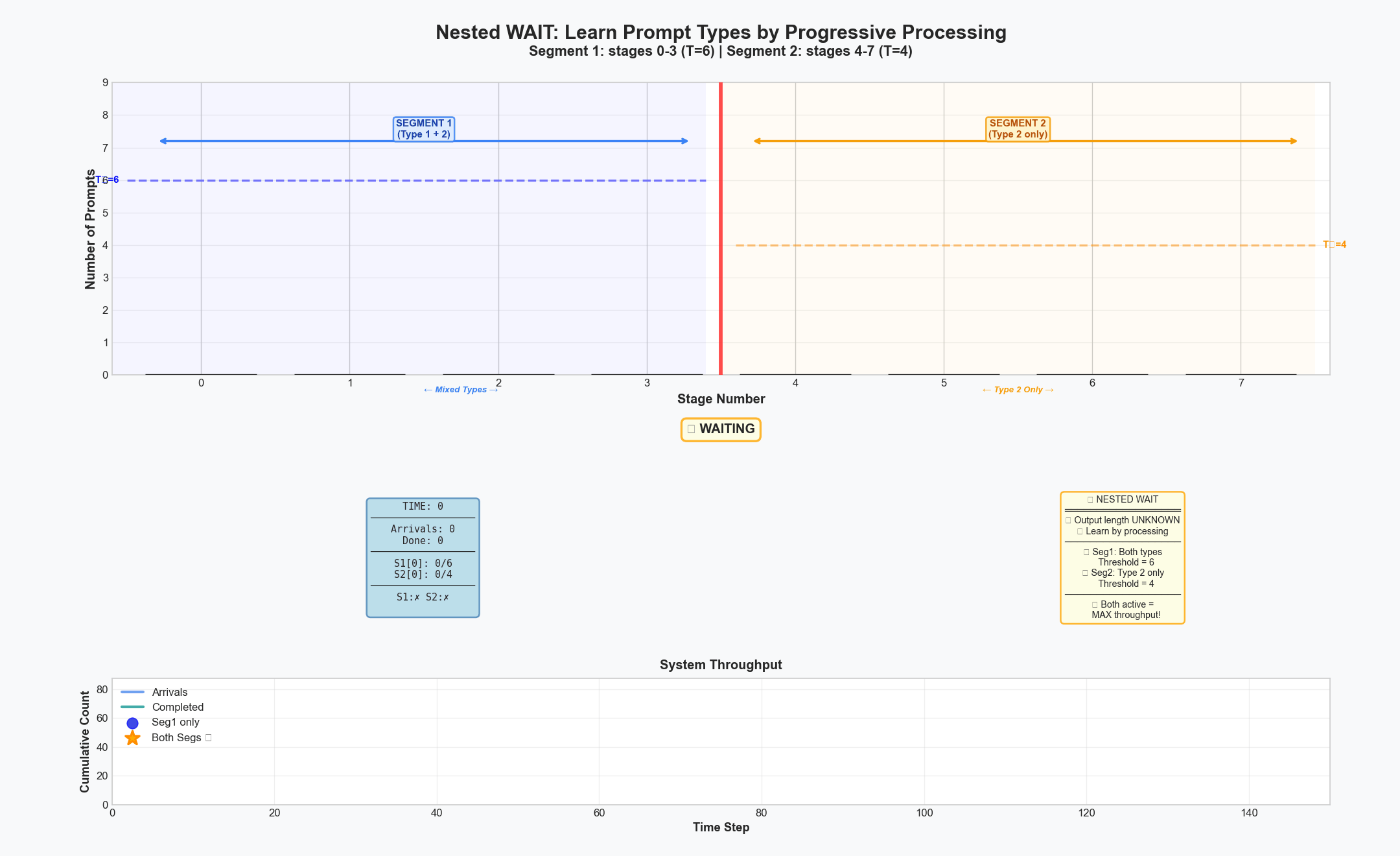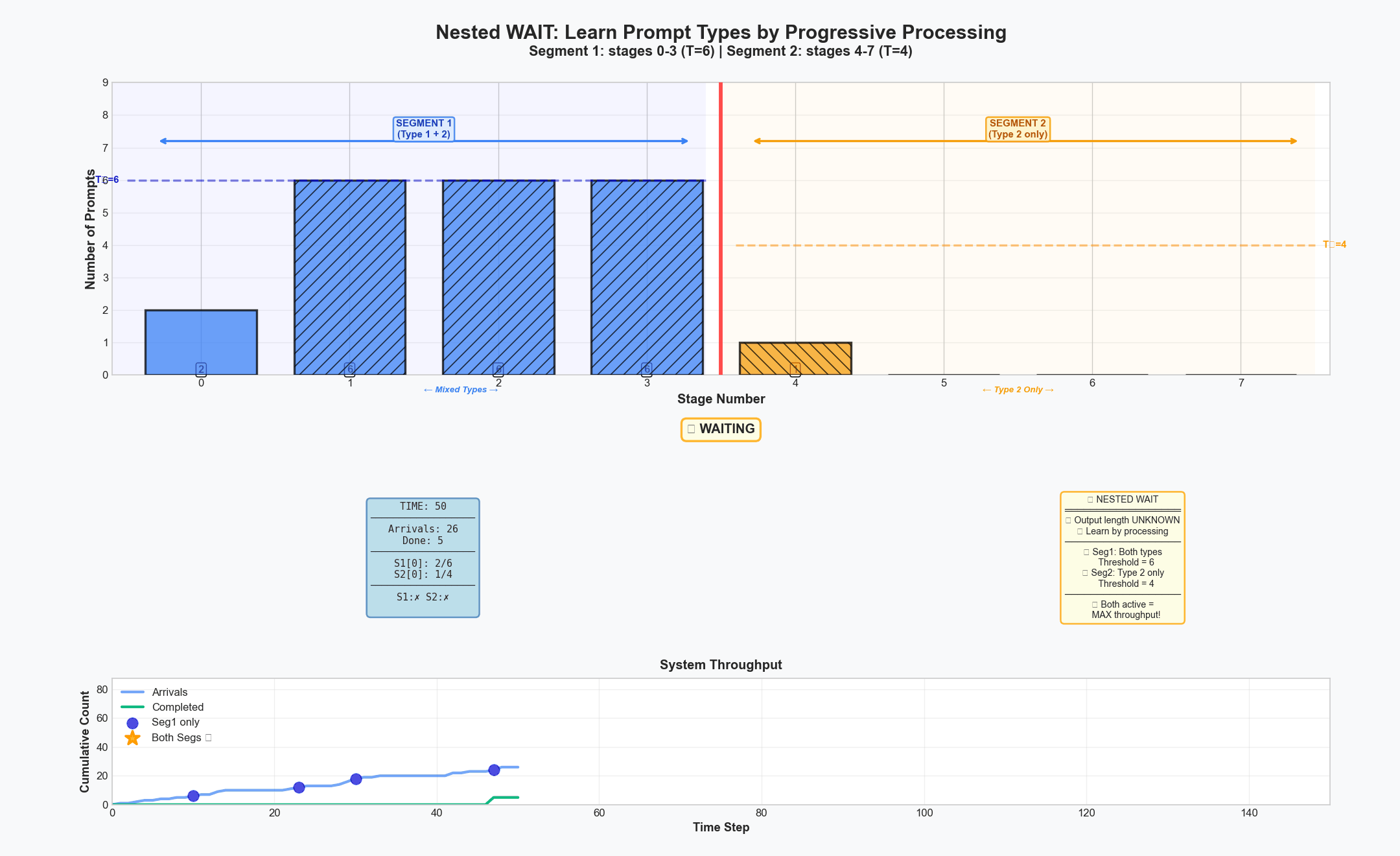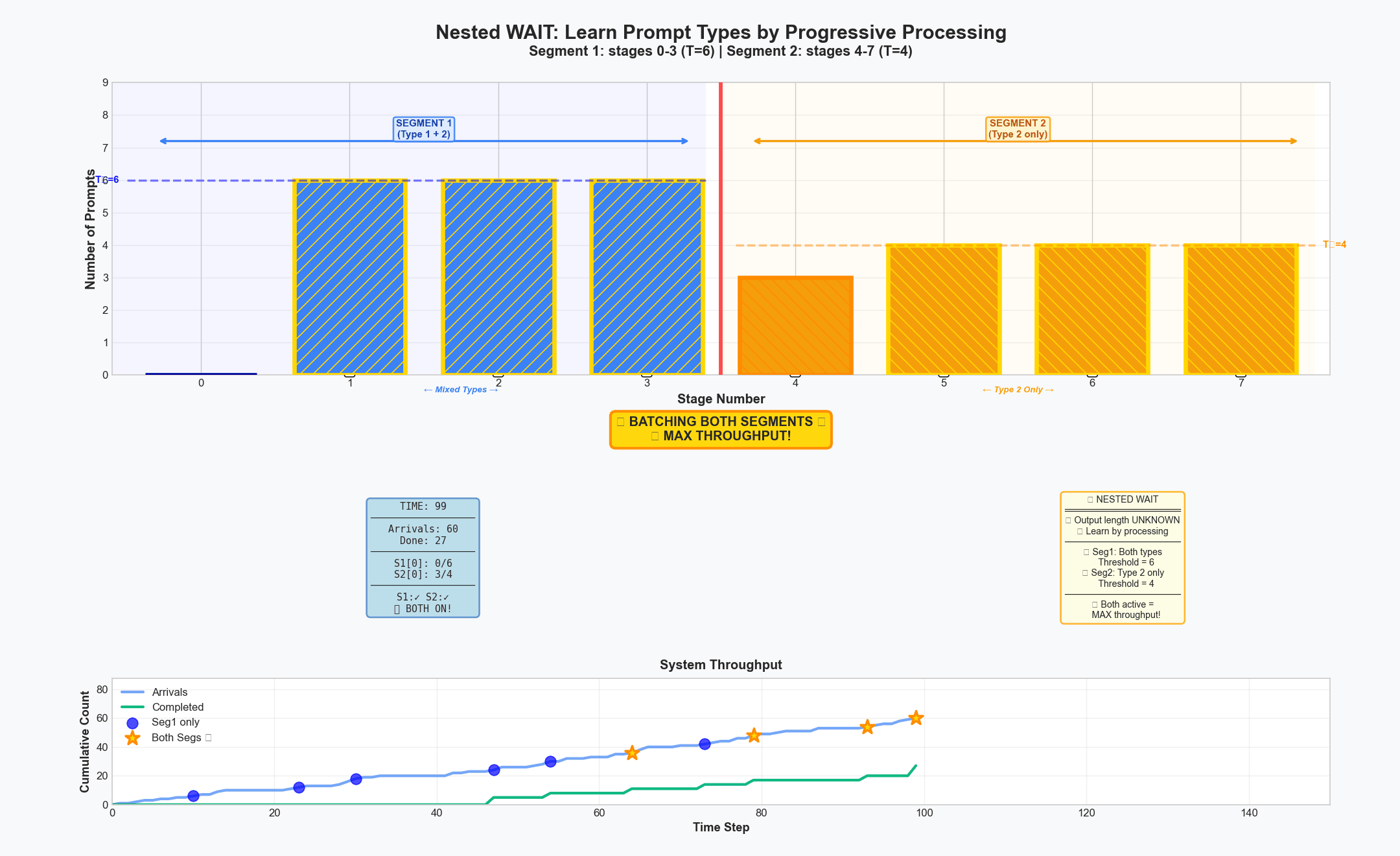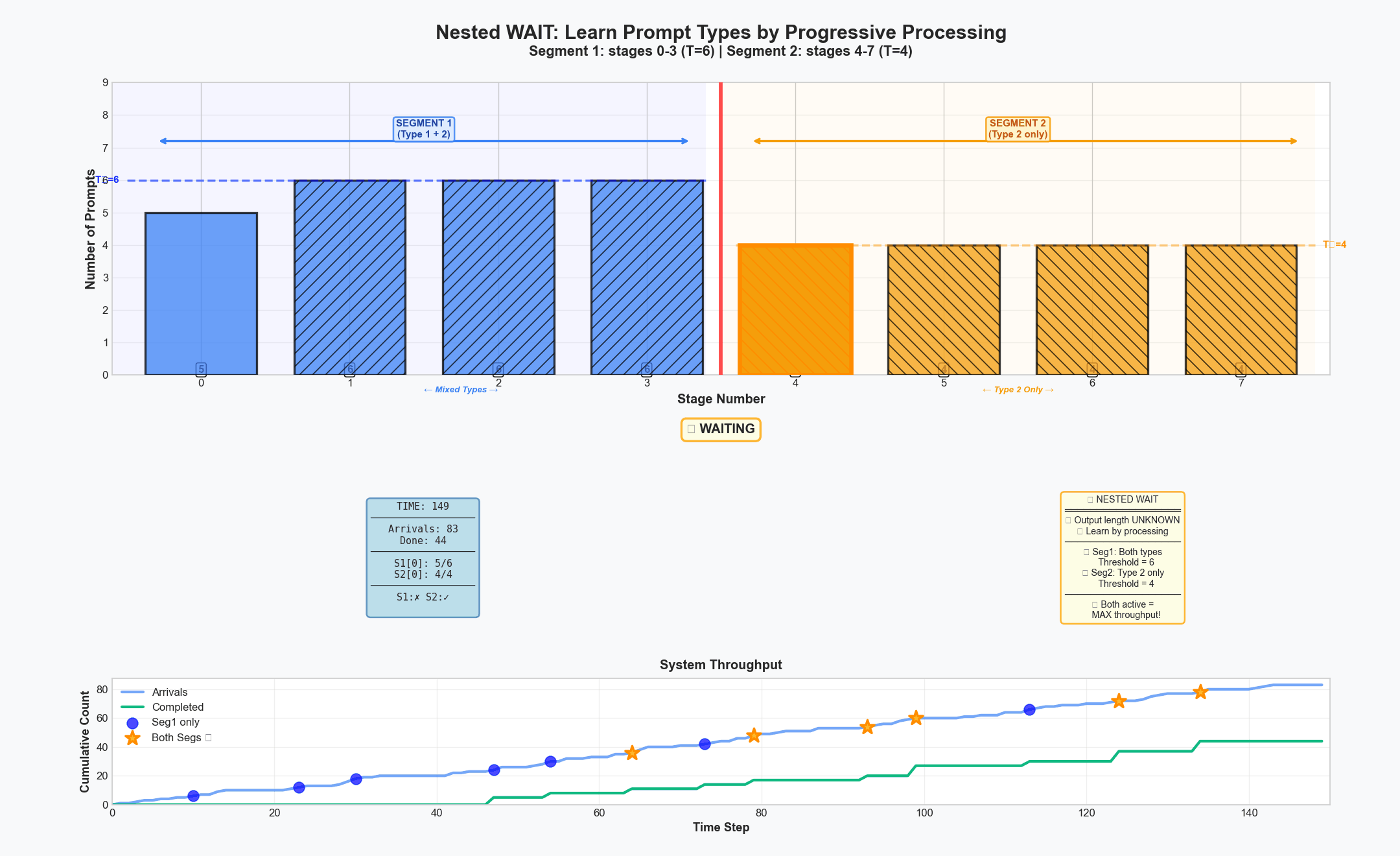
Nested WAIT Algorithm: progressively revealing information